FunASR实时语音识别部署和使用
FunASR 模型的整理和集成,Docker一键启动,能够实时识别语音输入,准确度非常高
项目地址:https://github.com/harry0703/AudioNotes
FunASR开源仓库: https://github.com/modelscope/FunASR
效果展示
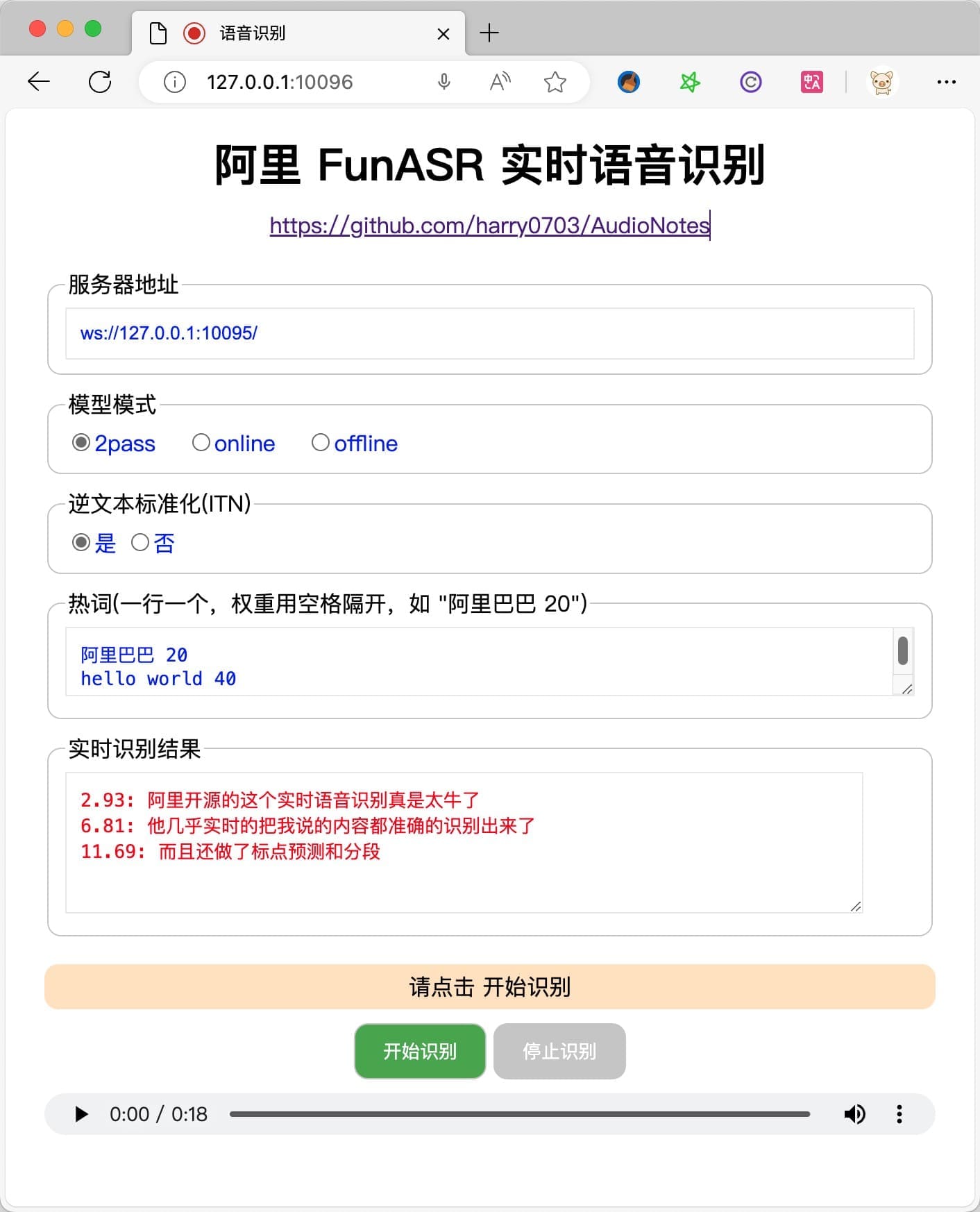
使用方法
Docker部署🐳
确保已经安装了Docker软件,没有的话,从官网下载安装 https://www.docker.com/products/docker-desktop/
复制以下代码到终端运行即可
注意:第一次启动过程可能会有点长,需要从魔搭下载4个模型
docker 启动后,访问 http://localhost:10096/
👉👉 如果你想了解更多,可以往下看
参数说明
① 模型模式
- 2pass: (默认)实时语音识别,并且句尾采用离线模型进行纠错(准确度更高)
- online: 实时语音识别
- offline: 一句话识别
② 逆文本标准化(ITN)
- 是: (默认) 表示进行逆文本标准化
- 否: 表示不进行逆文本标准化
逆文本标准化(Inverse Text Normalization, ITN) 是语音识别和自然语言处理领域的一种技术,用于将自动语音识别(ASR)系统生成的文本转化为更自然和可读的格式。这是对文本标准化(Text Normalization, TN)的逆过程。
逆文本标准化的目的
当语音被转换为文本时,ASR 系统通常会输出一种更标准化的文本形式。例如:
- 数字 “123” 可能会被识别为 “一二三” 或 “123”。
- 日期 “2024年7月25日” 可能会被识别为 “二零二四年七月二十五日” 或 “2024年7月25日”。
这些输出虽然标准化,但不一定是人们习惯书写或阅读的格式。 ITN 的作用是将这些标准化的文本转换回更自然、更符合书面习惯的形式。例如:
- “一二三” 转换为 “123”
- “二零二四年七月二十五日” 转换为 “2024年7月25日”
- “五千七百六十三” 转换为 “5763”
👉👉如果你想使用API,请参考以下文档
系统架构图
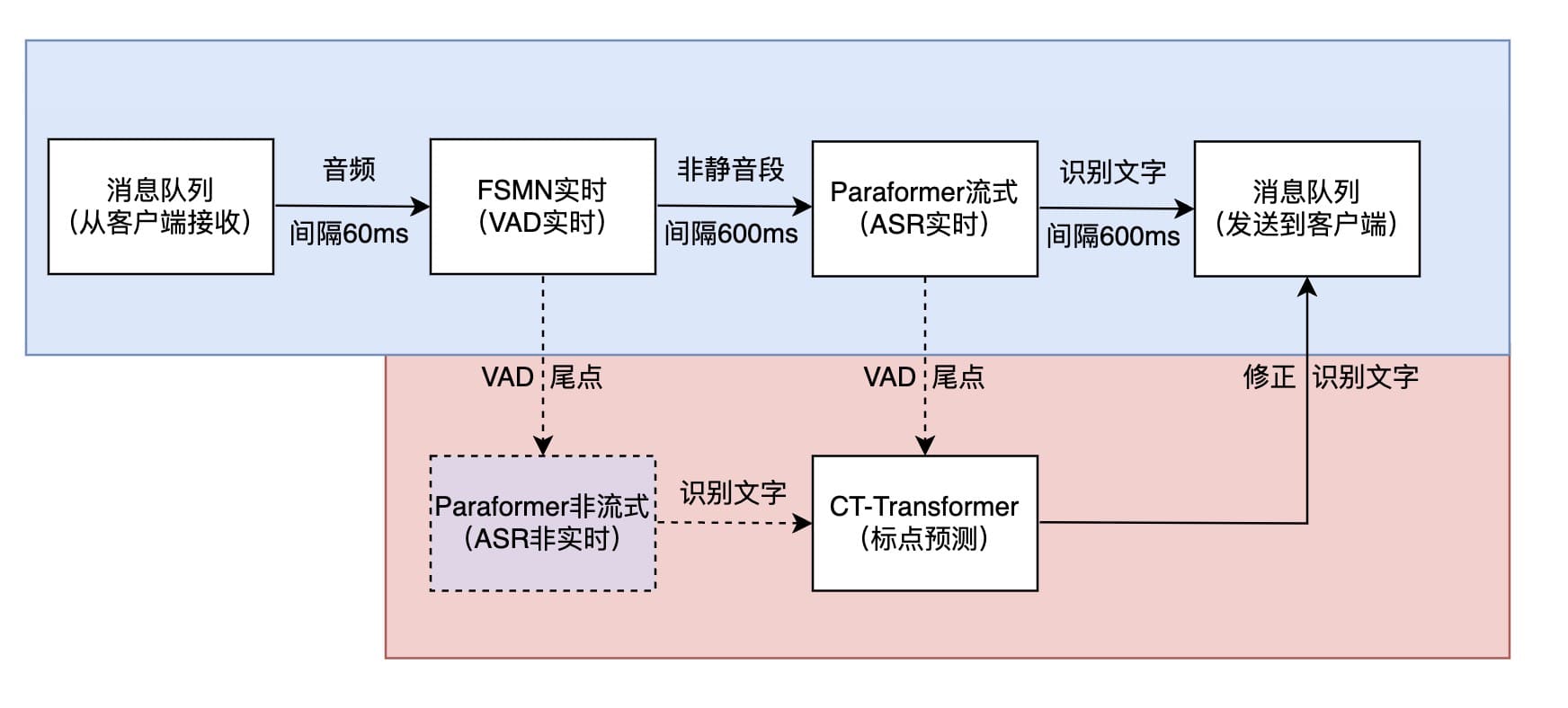
注意:
- 10096端口为网页界面
- 10095端口为websocket通信端口 >
🅰️ 从客户端往服务端发送数据
消息格式
配置参数用json,音频数据采用bytes
① 首次通信
客户端发送配置参数
参数说明:
wav_name:表示需要推理音频文件名wav_format:表示音视频文件后缀名,只支持pcm音频流is_speaking:表示断句尾点,例如,vad切割点,或者一条wav结束chunk_size:表示流式模型latency配置,[5,10,5],表示当前音频为600ms,并且回看300ms,又看300ms。hotwords:如果使用热词,需要向服务端发送热词数据(字符串),格式为 “{“阿里巴巴”:20,“通义实验室”:30}”itn: 设置是否使用itn,默认true
② 发送音频数据
直接将音频数据移除头部信息后,使用 bytes 数据发送,支持音频采样率为8000
③ 发送结束标志
音频数据发送结束后,需要发送结束标志
🅱️ 从服务端往客户端发数据
发送识别结果
识别中
识别结束
| |
参数说明:
mode:推理模式- 2pass-online:表示实时识别结果
- 2pass-offline:表示2遍修正识别结果
wav_name:需要推理音频文件名text:语音识别输出文本
👉👉踩坑
报错:录音open失败:浏览器禁止不安全页面录音
如果你是在其他电脑或服务器上部署的服务,而不是在本地,当你打开页面后,可能会遇到这个问题。
假设服务器IP是 192.168.1.170,打开的页面是 http://192.168.1.170:10096/
解决方法:
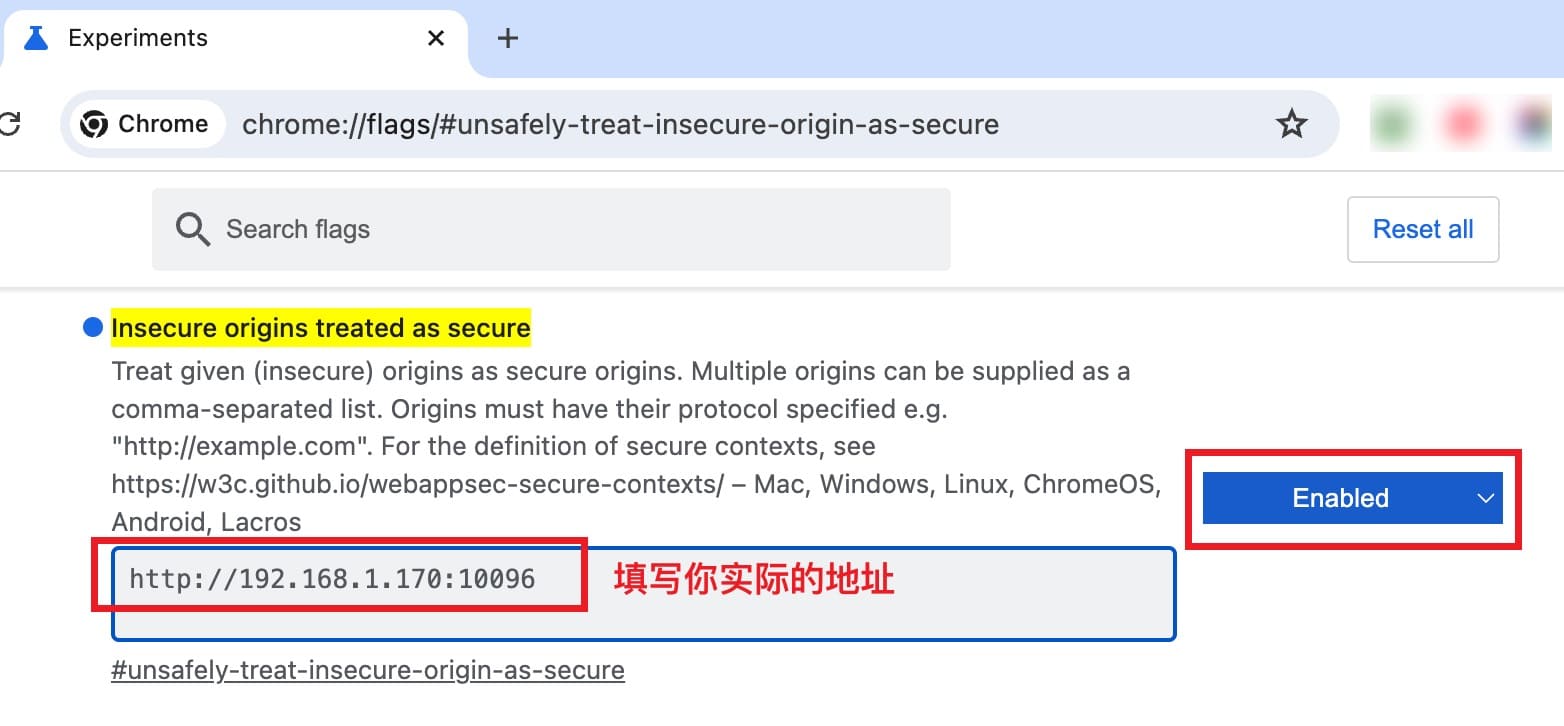
Chrome浏览器
- 在浏览器地址栏输入
chrome://flags/#unsafely-treat-insecure-origin-as-secure - 把
http://192.168.1.170:10096/添加到输入框内 - 将
Insecure origins treated as secure设置为Enabled - 重启浏览器
Edge浏览器
- 在浏览器地址栏输入
edge://flags/#unsafely-treat-insecure-origin-as-secure - 把
http://192.168.1.170:10096/添加到输入框内 - 将
Insecure origins treated as secure设置为Enabled - 重启浏览器