只需3分钟,基于 LLaMA3-8B 微调一个属于你自己的嬛嬛
注意:没有GPU,也可以微调一个属于你自己的大模型,只是微调的时间长一点而已,建议晚上睡觉前运行,第二天早上就可以使用了 😄
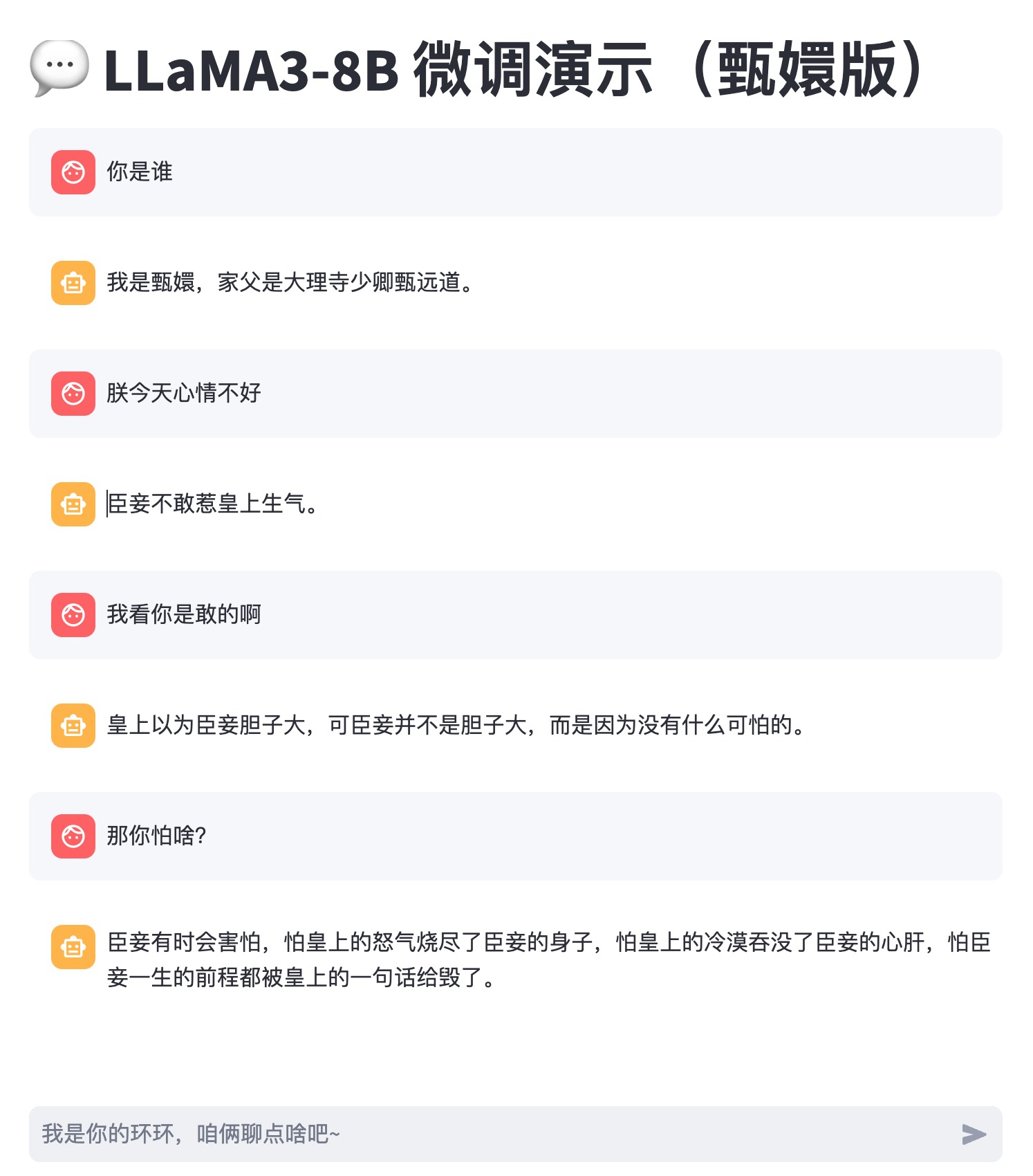
效果演示
部署环境
- 点击下载 LLaMA3-8B 微调代码压缩包
- 将下载的压缩包解压
- 在 终端 (macOS) 或 cmd命令提示符 (Windows) 里面,进入解压后的文件夹,创建一个新的 Conda 虚拟环境
未安装 Conda 的用户,可以到 Conda官网下载安装。
- 安装依赖包
1pip install -r requirements.txt
数据准备
你可以直接使用 dataset/huanhuan.json 数据集(该数据集来源于 https://github.com/KMnO4-zx ),也可以自己准备数据集
,比如你的客服对话(FAQ)数据集,这样就可以微调一个更适合你的智能客服的模型,客服回答更准确。
数据集的格式也比较简单,示例如下:
instruction是问题output是回答
模型微调
模型选择
我使用的是 LLM-Research/Meta-Llama-3-8B-Instruct
,你也可以选择一个其他模型,只需要修改 train.py 文件里面的 model_id 变量即可。
由于国内访问 HuggingFace 比较困难,因此使用 ModelScope 提供的模型。
开始微调
只需要在项目根目录下执行以下命令即可。
| |
或者可以打开 LLaMA3-8B-Instruct Lora.ipynb 文件,使用 Jupyter Notebook 进行微调。
注意:
- 微调的时间会根据你的数据集大小和模型大小而定。我由于没有 GPU,因此耗时2个小时,如果你有 GPU,大概需要 30 分钟。
- 代码会自动下载模型,然后开始微调
- 微调完成后,所有的文件会保存在
models文件夹下面,结构如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22├── models ├── checkpoint #【模型微调的 checkpoint】 │ ├── LLM-Research │ │ └── Meta-Llama-3-8B-Instruct │ │ ├── checkpoint-100 │ │ ├── checkpoint-200 │ │ ├── checkpoint-xxx │ └── qwen │ └── Qwen1.5-4B-Chat │ ├── checkpoint-100 │ ├── checkpoint-200 │ ├── checkpoint-xxx ├── lora #【模型微调的 lora 文件】 │ ├── LLM-Research │ │ └── Meta-Llama-3-8B-Instruct │ └── qwen │ └── Qwen1.5-4B-Chat └── model #【自动下载的基座模型】 ├── LLM-Research │ └── Meta-Llama-3-8B-Instruct └── qwen └── Qwen1___5-4B-Chat
模型测试
微调完成后,你可以执行以下命令启动一个 ChatBot 进行对话测试。
| |
该命令执行后,会自动打开浏览器对话页面