FlashVoice:我为什么要做一个本地优先的语音输入法
这段时间,我一直在打磨 闪录(FlashVoice)。
它不是一个“所有功能都帮你想好”的语音产品,而更像是一个安静地待在系统底层、随时可用的语音输入工具。
一个很简单的起点
我最初只是想解决一个非常具体的问题:
当我在任何应用里说话时,
能不能直接把我的话,准确、快速、可控地变成文字?
不需要上传音频,不需要切换页面,也不希望被绑定到某一家云服务。
为什么是「本地优先」
在做语音相关产品的过程中,我越来越明确一件事:
- 语音 ≠ 普通文本
- 它包含环境、情绪、隐私,甚至是无意识的信息
所以 FlashVoice 的很多设计选择,其实并不“激进”:
- 能在本地跑的,尽量本地跑
- 模型由用户选择,而不是由产品决定
- 不强制联网,也不默认上传数据
这让产品在一开始看起来“没那么亮眼”,但长期来看,我更安心。
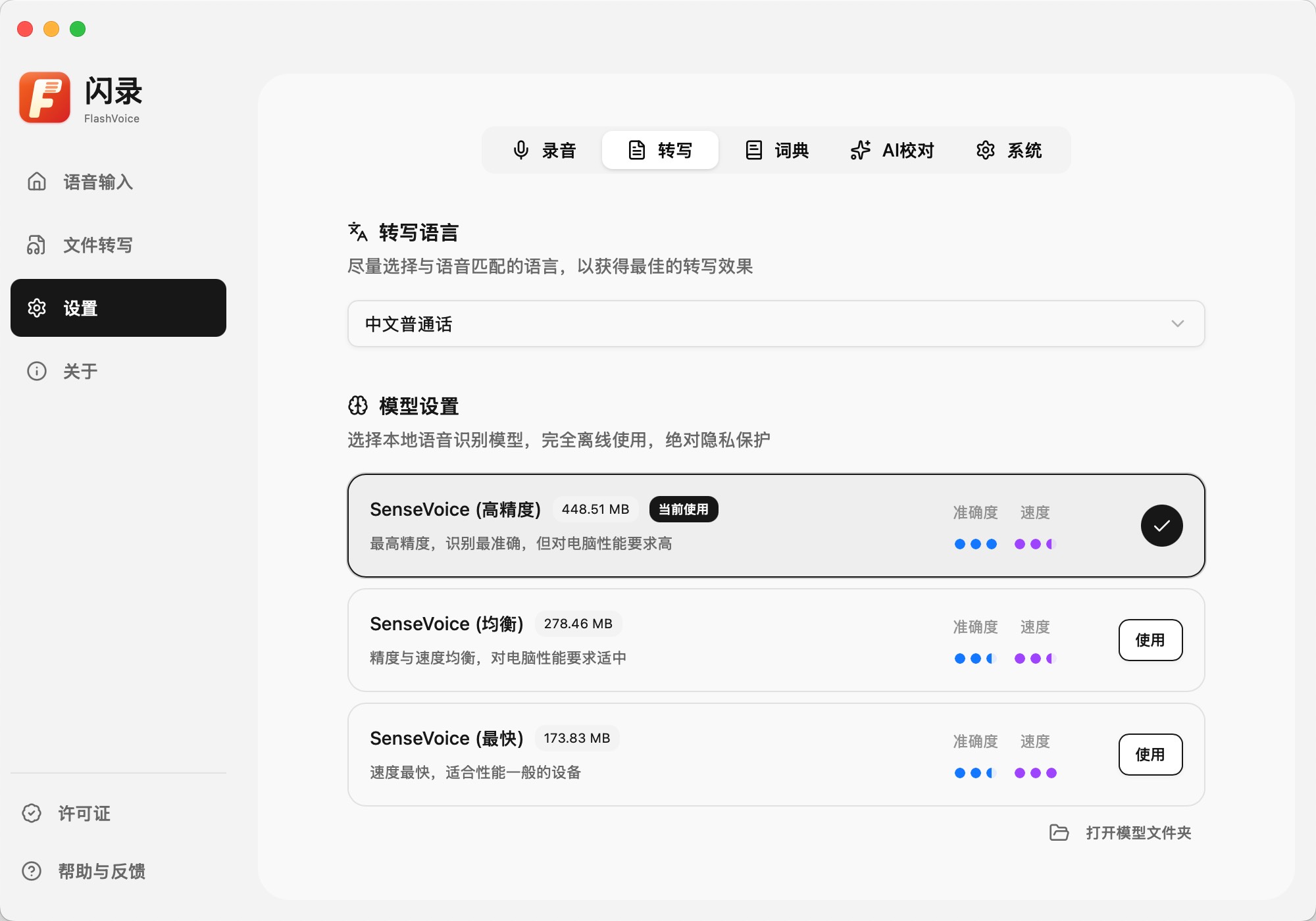
关于模型这件事
FlashVoice 并不试图押注某一个模型。
相反,它更像是一个模型的使用层:
- 可以接入云端模型
- 也可以使用本地部署的 STT / LLM
- 用户清楚地知道:现在用的是谁,在做什么
我不太认同“模型即产品”的叙事。
模型会变,但输入体验和信任关系会留下来。
它现在还不完美
目前 FlashVoice 仍然在快速迭代中:
- 有些交互还不够顺
- 有些系统权限配置并不友好
- 文档也在慢慢补齐
写在最后
只是想记录一下:
我为什么愿意花时间,把 FlashVoice 慢慢做下去。
如果你也在意输入体验、本地计算、或者对语音这件事有自己的执念——
那我们大概在同一条路上。
FlashVoice 是我目前正在打磨的一款语音输入工具。
如果你对本地优先、隐私友好的语音输入方式感兴趣,可以在这里了解更多:
https://flashvoices.com/zh