阿里开源 CosyVoice 语音克隆 部署和使用
应该是 开源界 音色 最稳定 的语音合成和克隆模型了,支持预训练音色合成、自然语言控制、3秒极速复刻和跨语种复刻。
官方部署方式比较复杂,错误较多,我这里进行了整理和优化,支持GPU和CPU,方便大家使用。
CosyVoice 开源仓库: CosyVoice
效果展示
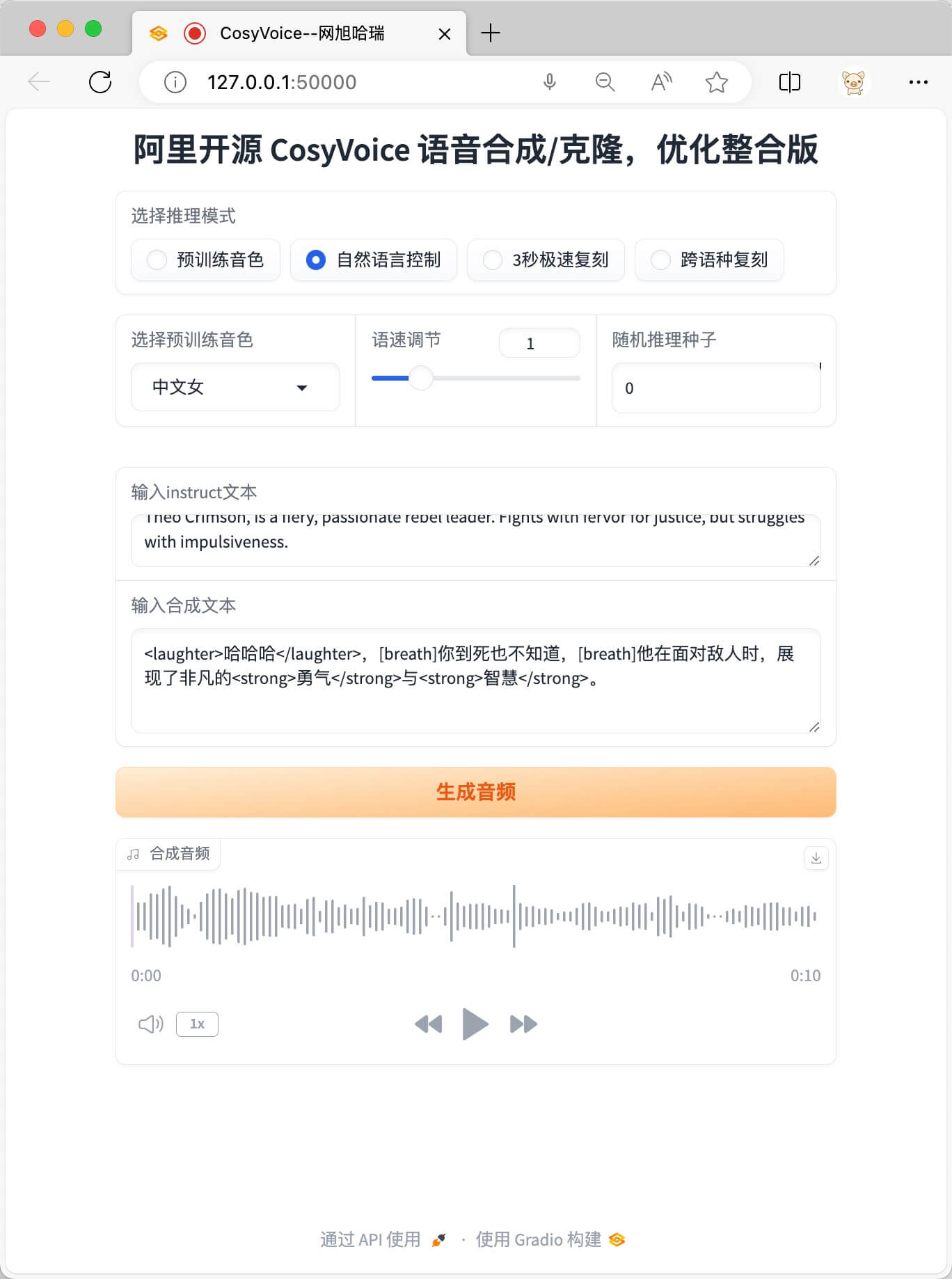
自然语言控制
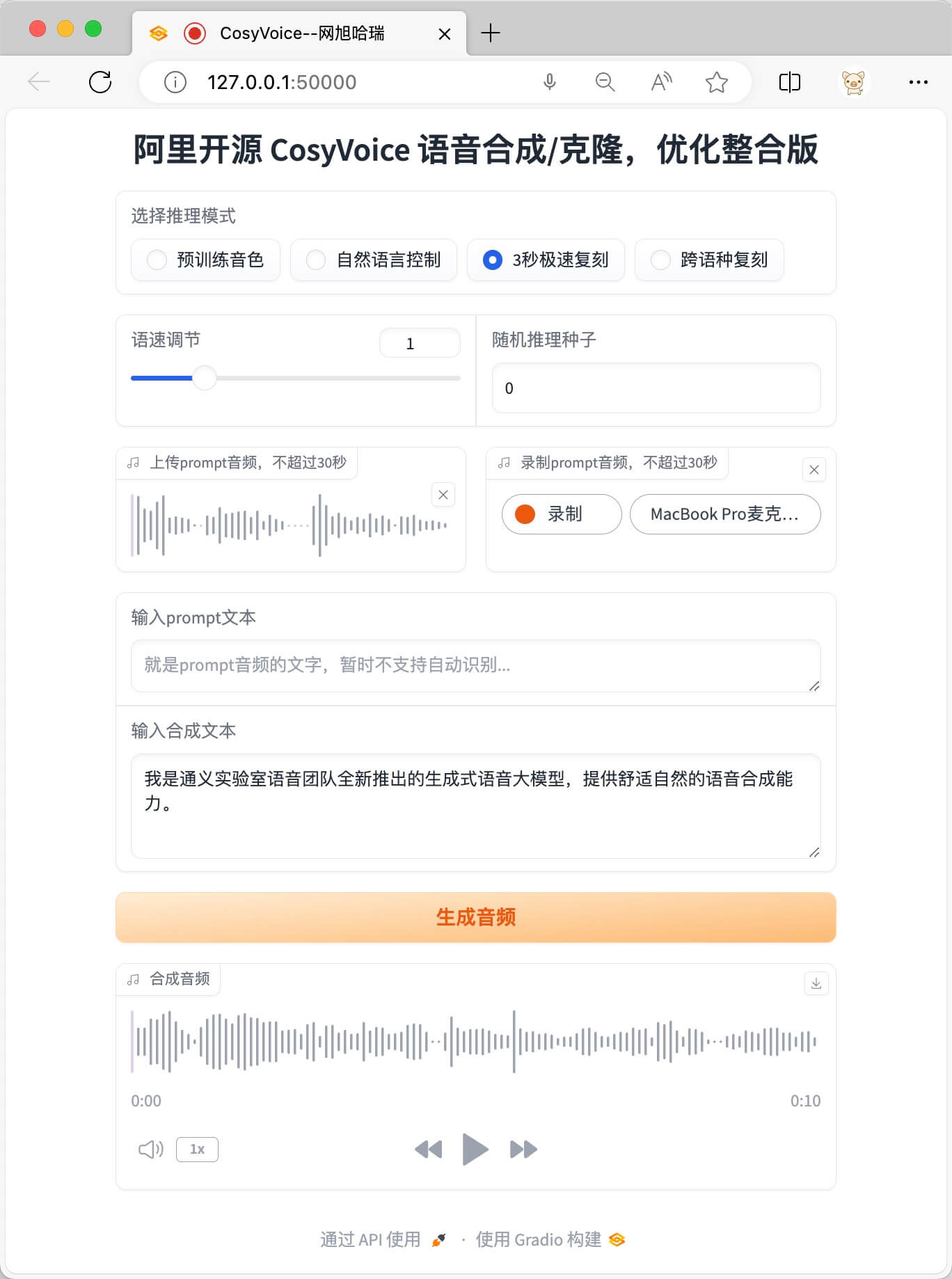
3秒极速复刻
使用方法
均支持 GPU 和 CPU
第一次启动过程可能会有点长,需要从魔搭下载3个模型
Windows 一键启动包
百度网盘: https://pan.baidu.com/s/1UTuRKPQ9nuQk69qxQzdL4A?pwd=j2ei 提取码: j2ei
- 下载后使用 7z 解压。没有 7z 的话,可以在这里下载:https://7-zip.org/download.html
- 双击
双击启动.bat启动服务 - 启动后,访问 http://127.0.0.1:50000/
注意:文件夹中不能有 中文、特殊字符和空格,否则可能会启动失败
Docker部署🐳
确保已经安装了Docker软件,没有的话,从官网下载安装 https://www.docker.com/products/docker-desktop/
复制以下代码到终端运行即可
CPU 版本
GPU 版本
docker 启动后,访问 http://127.0.0.1:50000/