如何利用本地模型,将音视频整理成一份结构化的Markdown笔记
项目地址:https://github.com/harry0703/AudioNotes
基于 FunASR 和 Qwen2 构建的音视频转结构化笔记系统
能够快速提取音视频的内容,并且调用大模型进行整理,成为一份结构化的markdown笔记,方便快速阅读
FunASR: https://github.com/modelscope/FunASR
Qwen2: https://ollama.com/library/qwen2
效果展示
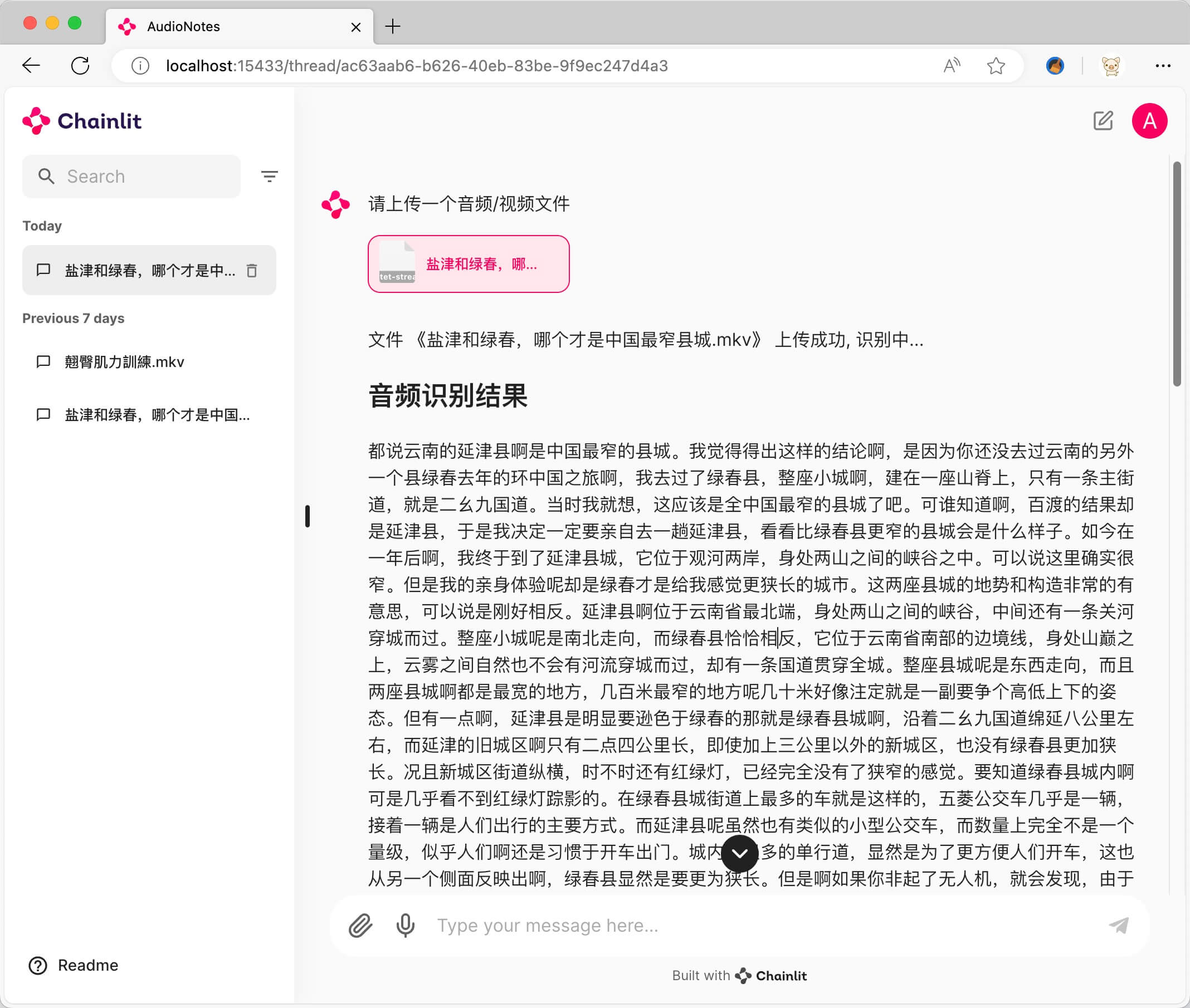
音视频识别和整理
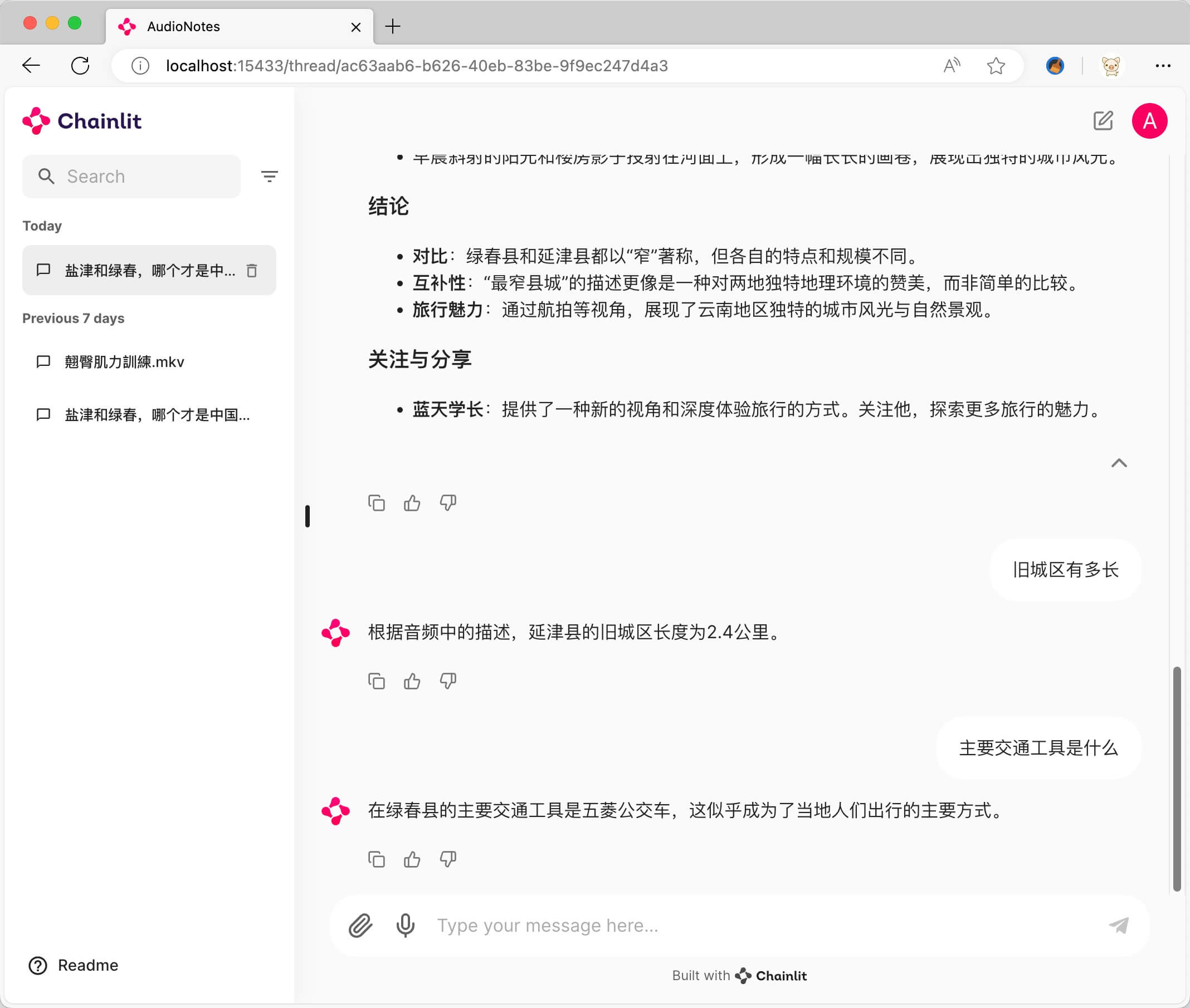
与音视频内容对话
使用方法
① 安装 Ollama
下载对应系统的 Ollama 安装包进行安装
② 拉取模型
我以 阿里的千问2 7b 为例 https://ollama.com/library/qwen2
| |
Docker部署(推荐)🐳
docker 启动后,访问 http://localhost:15433/
登录账号为 admin,密码为 admin (可以在 docker-compose.yml 文件里面修改)
本地部署 📦
需要有可访问的 postgresql 数据库
将 .env.example 重命名为 .env,修改相关配置信息
| |
服务启动后,访问 http://localhost:8000/
登录账号为 admin,密码为 admin (可以在 docker-compose.yml 文件里面修改)