阿里开源 CosyVoice 语音克隆 部署和使用
应该是 开源界 音色 最稳定 的语音合成和克隆模型了,支持预训练音色合成、自然语言控制、3秒极速复刻和跨语种复刻。
官方部署方式比较复杂,错误较多,我这里进行了整理和优化,支持GPU和CPU,方便大家使用。
应该是 开源界 音色 最稳定 的语音合成和克隆模型了,支持预训练音色合成、自然语言控制、3秒极速复刻和跨语种复刻。
官方部署方式比较复杂,错误较多,我这里进行了整理和优化,支持GPU和CPU,方便大家使用。
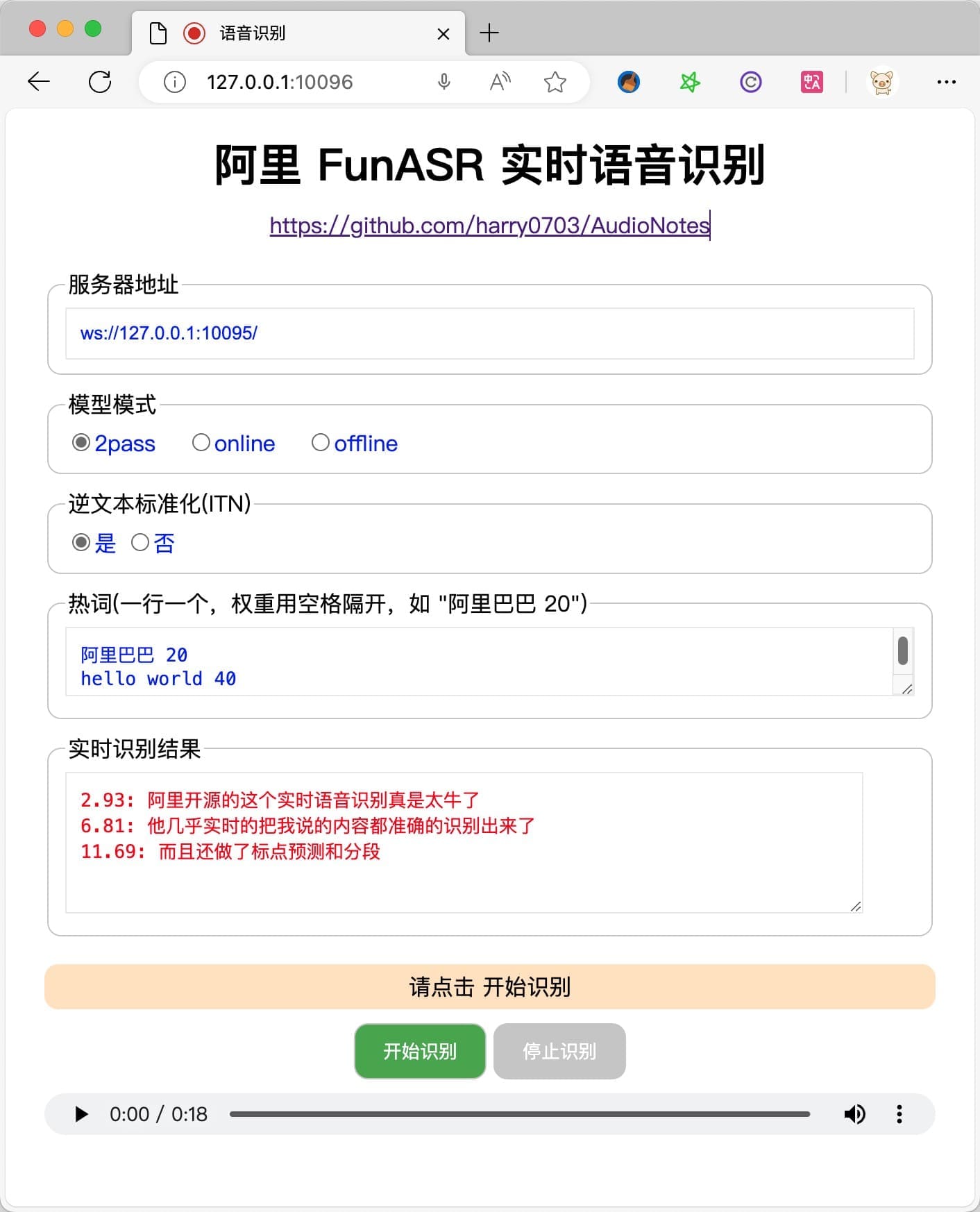
FunASR 模型的整理和集成,Docker一键启动,能够实时识别语音输入,准确度非常高
项目地址:https://github.com/harry0703/AudioNotes
FunASR开源仓库: https://github.com/modelscope/FunASR
确保已经安装了Docker软件,没有的话,从官网下载安装 https://www.docker.com/products/docker-desktop/
项目地址:https://github.com/harry0703/AudioNotes
能够快速提取音视频的内容,并且调用大模型进行整理,成为一份结构化的markdown笔记,方便快速阅读
项目地址:https://github.com/2noise/ChatTTS
Windows 用户建议直接下载一键启动包,运行环境和模型都已经配置好,使用更简单。
百度网盘下载:https://pan.baidu.com/s/1wfdqQDTzDnMf01bV1wzKgQ?pwd=v2kb 提取码:v2kb
解压密码:harryai
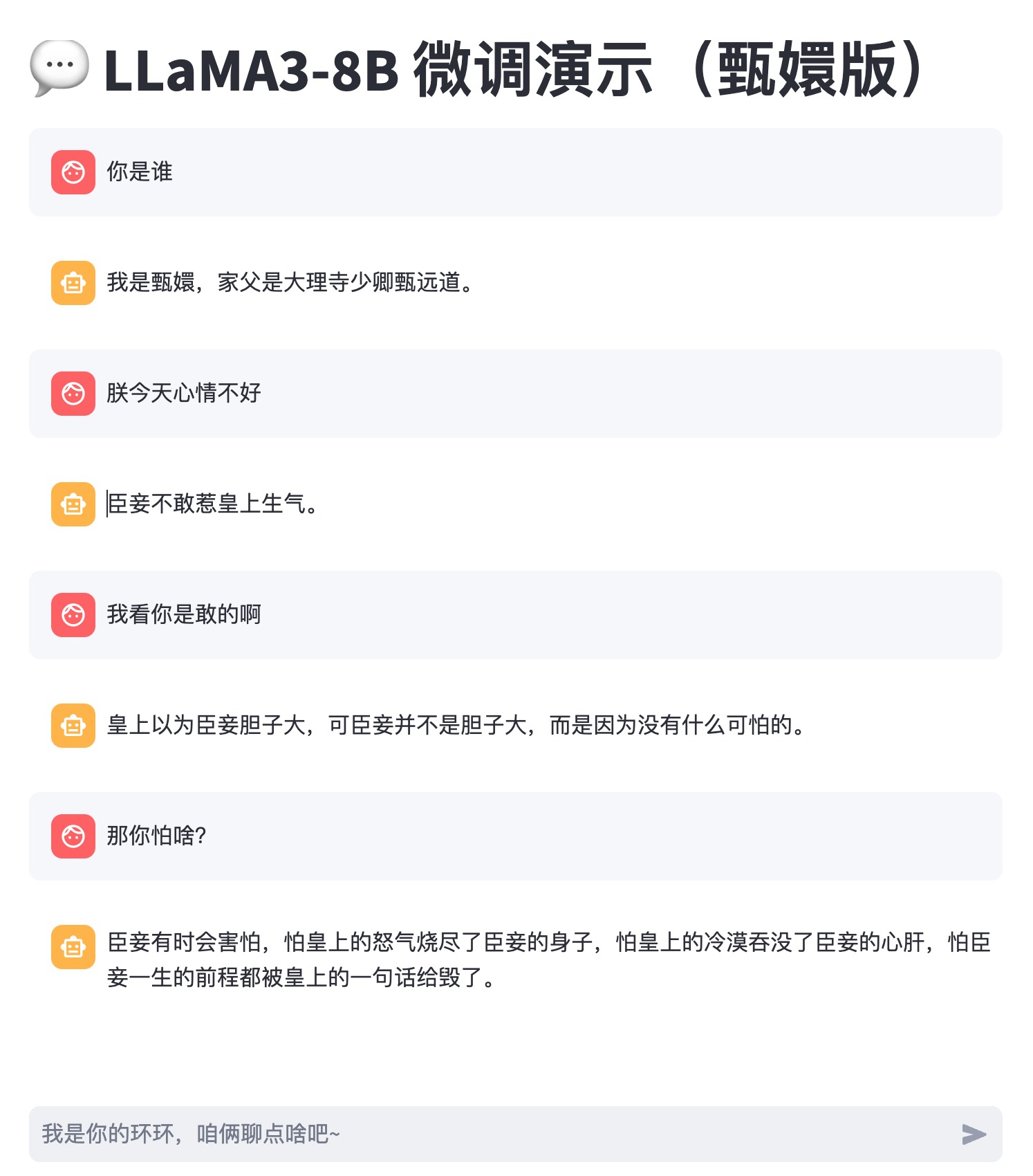
注意:没有GPU,也可以微调一个属于你自己的大模型,只是微调的时间长一点而已,建议晚上睡觉前运行,第二天早上就可以使用了 😄
未安装 Conda 的用户,可以到 Conda官网下载安装。
前提
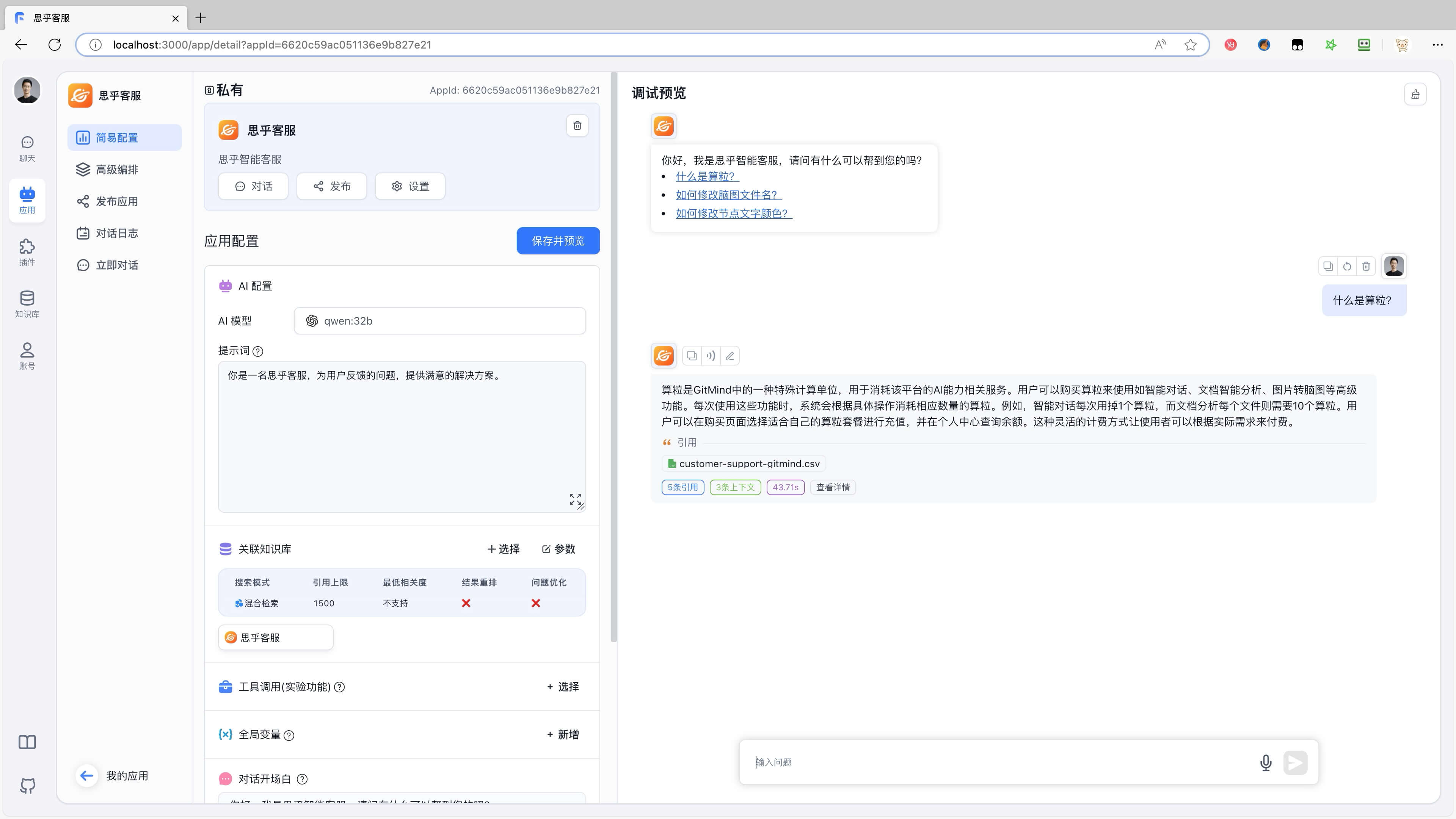
先搭建好 本地化的企业级知识库问答系统 ,参考 《手把手教你构建一个 本地化的,免费的,企业级的,AI大模型知识库问答系统》
因为 ChatGPT-On-WeChat 代码有 Bug,作者一直未修复,因此我修改后,重新打了一个Docker镜像,避免大家踩坑。
打开 docker-compose.yml 文件,修改 OPEN_AI_API_KEY 和 OPEN_AI_API_BASE 为你的 FastGPT 的 API Key 和 API 地址。
我将通过一个系列分享,手把手的教大家打造一个完全本地化的,免费的,企业级知识库问答系统
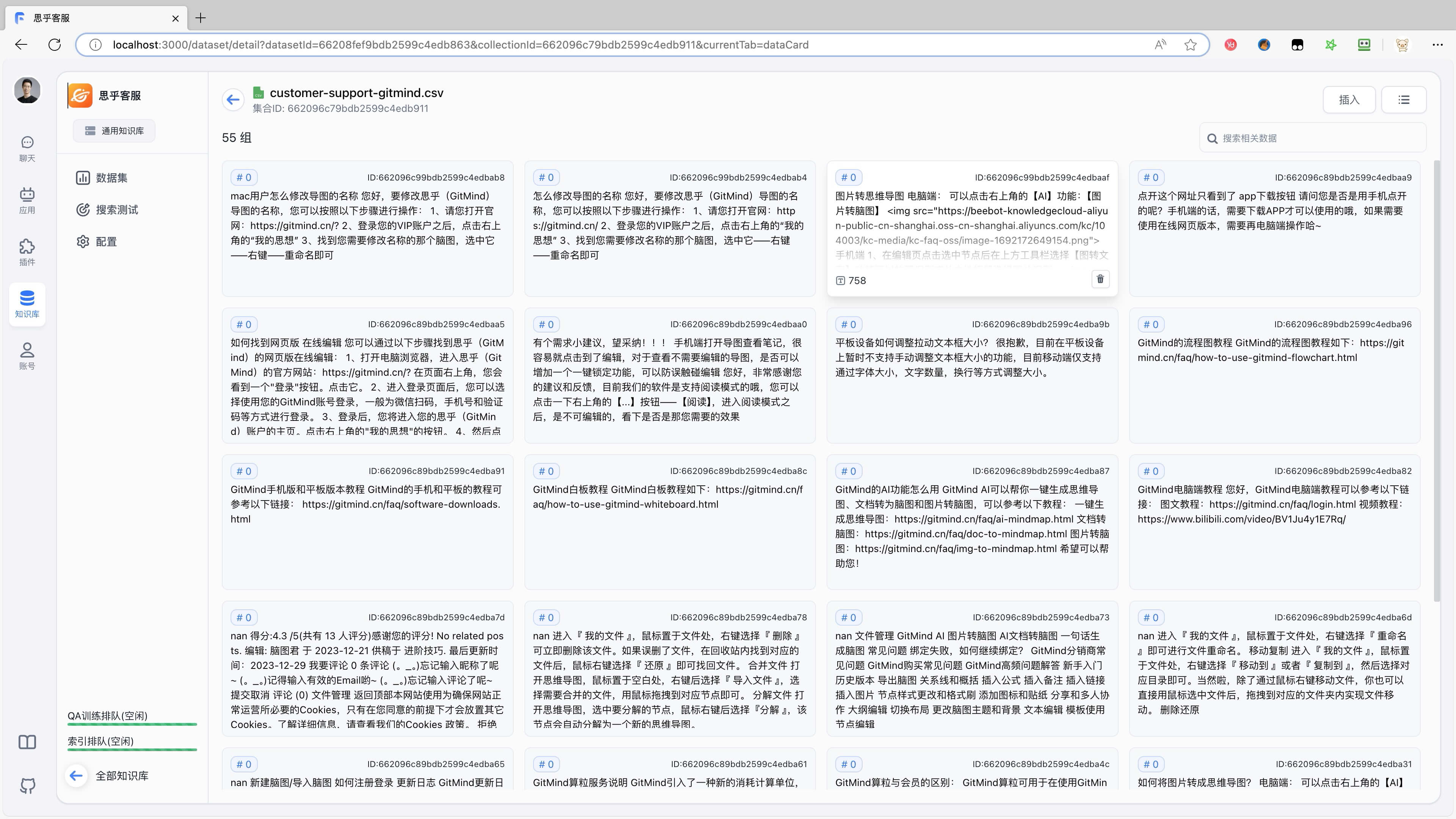
当使用外部模型或服务时,我们的私有数据,用户问题,都会被发送给第三方 那我们就要面临私有数据暴露给别人的风险,甚至会导致数据泄露 本地化会让我们的数据就更安全